
Introduction
“AI” is everywhere. I don’t have to tell you twice. It’s Q4 2024! There are Anthropic ads at the airport and Gemini commercials during major sporting events. Kids say “ChatGPT it” instead of “Google It.” So…yeah, it’s everywhere and (don’t quote me on this), it might actually be moving beyond the early adopter phase. With that in mind, I won’t talk about it from either the doomer or shill “AGI” perspective today. There’s enough of that out there. Instead, we’re going to take a far more pragmatic approach and look at a prevalent system design pattern for generative AI applications: Retrieval Augmented Generation (or RAG). This will be a particularly grounded and sort of hands-on keyboard case study, so I’ll assume that anyone reading this (technical or business-facing) is not just knowledgeable on AI trends, but has enough competence to know the current limitations of these applications, their impacts on product, and is just generally a bit more experienced compared to someone who’s merely played with Claude a couple times.
Ok, but WTF is RAG really?
Before diving in, let’s set some context. In short, RAG is a technique and design pattern optimized to provide relevant context to a generative model. In even shorter, as Hamel Husain puts it, “RAG -> Provide relevant context.” It’s a technique to ground generative output with context to minimize hallucinations, enable few-shot learning, and provide updated data without retraining or fine-tuning.
Let’s explore this concept further. Here are relevant questions to maximize this technique: How do we provide context? Where is it coming from? What makes it relevant? These lead down extremely deep paths that could have their own stand-alone pieces (hint: that’s called foreshadowing). We won’t explore each one to that level, but we’ll cover real-life examples of how to approach each.
Retrieval, or “R”
We’ll go letter by letter. Retrieval is, in so many words, a “new” look at search technology. It comes down to: there is data (“context”) in a database that needs to be queried (“retrieved”) accurately and relevantly. This particular section of the system has had previous gold rushes (see uh Google), so there are a lot of best practices, products, and standards that provide a robust foundation for development. We’ll cover some of these, focusing on techniques I’ve used in the wild.
First, let’s cover the most buzz word-heavy part of retrieval. The tools of this particular trade are databases, specifically a type designed to store vector embeddings. Embeddings are another completely different path you can dive deeper into, but for the sake of this piece, just keep in mind that this type of data is:
Representations of semantic data (like words, sentences, or even images) as ordered lists of numbers (vectors) where similar items exhibit similar numerical patterns.
The surge in generative AI interest has led to a rise in specialist databases for this type of storage, with popular names including ChromaDB, Pinecone, Weaviate, and FAISS. They have different pros and cons, but the overall theme is that these are “modern, AI-native” specialized databases. The other options are extensions or additions to traditional databases, like Mongo Atlas & Postgres, which offer vector storage, indexing, and retrieval capabilities as part of their overall product offering. MongoDB is the leader in NoSQL and Postgres and pg vector are the main names in SQL. This piece will not get into the nitty-gritty of which is better, since everyone operates under vastly different contexts. I think the key is identifying your legacy infrastructure (if any) and making the decision that balances budget, integration, and internal strengths. As a quick anecdote, I’ve explored all the ones named in this piece so far and found that pgvector really hits a nice balance between existing client infrastructures (which tend to be SQL-based), expanding capabilities (it supports a wide variety of the modern gen AI use cases, i.e., hybrid search), and maximum resource leverage (it’s open source!).
After you get the database discussion out of the way, retrieval becomes a game of relevance. The goal should be to create a system that supports rapid iteration, tests, and tweaks since “relevance” is a fluid and evolving concept. That starts with the initial data schema. For example, let’s say your RAG use case involves storing unstructured data from large, text-heavy documents such as transcripts from earnings calls or agency filings. Users will need to pull specific key word matches and search through the semantic meaning of certain phrases or sentences. This requires granular (almost sentence-level) searching and converting the contents from string text to vector embeddings. This conversion is done with embedding models, usually offered by the large providers (i.e. OpenAI, Anthropic) or options from a fairly robust open-source community. The mechanics of this process are out of scope for this guide, but the idea is basically that the process that inserts a document and its data will also run that conversion and insertion.


A naive implementation for something like this (and common in demoware) is storing the document in file in some sort of blob service and storing the URL and entire content as one entry in a table, something like:
Document Table
id: UUID, PK
doc_file_name: str
doc_file_url: str
doc_text_content: str
doc_vector_content: vector
This works initially, but it opens a giant can of worms for any real-world scenario, for example:
What happens if a document is extremely long? Most embedding models have a content processing limit, so you’ll likely hit that limit with documents over a certain size using this strategy.
How do you preserve the signal of a relevant section in a noisy, irrelevant document?
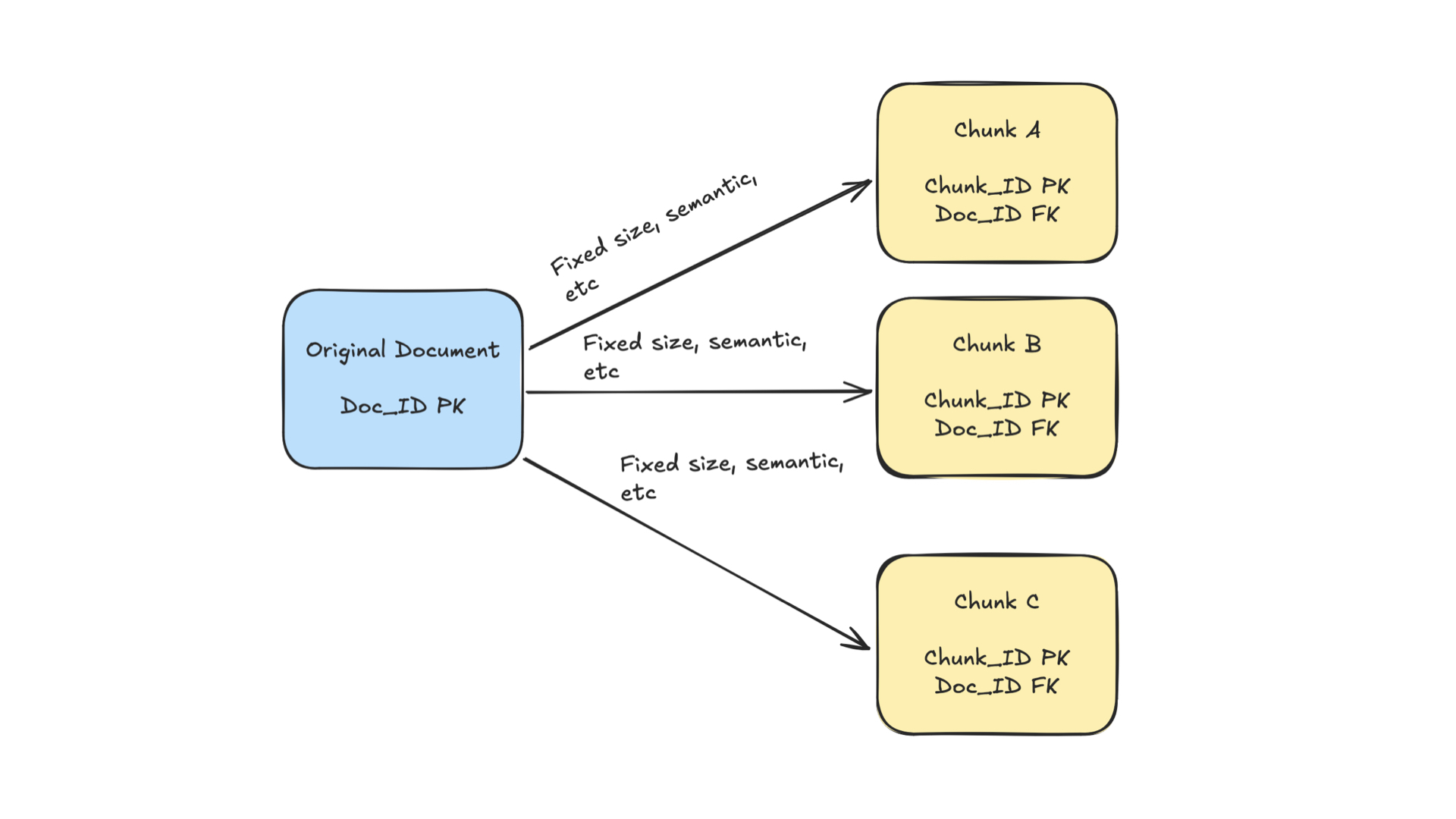
One common solution to the limit problem is chunking the document, which means splitting the content based on some condition, turning one document into several chunks. Again, this specific section could be an entire piece by itself, but generally speaking, the best way to think about chunking is connecting it to the unique nature or circumstances of your use case. If your documents and use case are straightforward, you can do fixed-size chunking and define a chunk size (i.e., 500 characters). Another approach for cases where the documents are consistent in format and structure is chunking based on that structure (i.e., the first paragraph header after a line break followed by X amount of sentences is where a chunk starts and ends). On the other hand, if your documents are inconsistent in structure and have very semantically rich content, consider chunking based on that semantic content. That’s a bit more complicated to implement, but it requires splitting up your chunks by their semantic scores so that each might be different size or length but includes the most semantically relevant content in each chunk. Regardless of the chunking technique, you’ll likely end up with a table structure that reflects something like this:
Document Table
doc_id: UUID, PK
doc_file_name: str
doc_file_url: str
doc_text_content: str
Document Chunk Table
chunk_id: UUID, PK
doc_id: UUID, FK
chunk_text_content: str
chunk_vector_content: vector

This data reflects a parent-child relationship, where a whole document is stored in one table and its chunks (along with vector content) are stored in a separate table. That design supports a search implementation that mitigates the issues outlined above in several ways:
Storing the parent document and its chunks with a foreign key relationship allows us to handle documents of any size, as a properly built indexing process should avoid a single chunk hitting an embedding model limit.
We can maintain granular semantic meaning in a more isolated context, since we can run our search process on the chunk content. Due to the foreign key relationship, it’s relatively simple to search over the individual chunks and return the whole document if needed.

That’s just the initial database design and chunking strategy! There are many other aspects of retrieval that can be explored. Let’s examine the search component itself. If we continue our earlier example (which assumes a Postgres RAG implementation), we can now take a look at how to craft the appropriate queries based on the search type, broadly grouped as:
A) Lexical Search: The first type of search that usually comes to mind, lexical can also be thought of as “key word search.” This category examines the actual characters and words in a query and can range from something as simple as “SELECT * WHERE (x) LIKE” to something more complex like a BM25 (Best Match 25) ranking function that accounts for document length and term saturation. The key idea that binds all these kinds of implementations is that under the hood, we’re trying to match the terms, characters, and words in the query to the terms, characters, and words in the data.
B) Semantic Search: this is the newest buzzword search you’ve seen on a viral LinkedIn post or Twitter thread. Unlike lexical or key word search, the techniques and algorithms of semantic search focus on comparing meaning and concepts, even when exact words or terms may not match. You can really think of this as searching by vibes. As mentioned in the earlier section, this technique requires transforming text into numerical vectors that capture vibes // meaning based on the underlying language model’s understanding of contextual relationships between words and concepts, allowing us to find similar content even when the words differ.
C) Hybrid Search: this combines the two schools. The core idea is combining techniques and approaches from both lexical and hybrid to achieve the best of both worlds. Think of it as using both a dictionary and a thesaurus - you gain the accuracy of exact word matching along with the flexibility of discovering related concepts. There are various implementation strategies, but common approaches include:
Computing and combining relevance scores from both lexical and semantic searches.
Using fast lexical search to create a candidate set, then refining with semantic search.
Dynamically adjusting the balance between lexical and semantic matching based on query characteristics.
As you can see, the retrieval space is dense, with many areas to explore. From the broader perspective of the complex system, it’s just the beginning. Next comes the augmentation aspect of things.
Augmented, or “A”
The “A” section here represents the delivery of the retrieved data from the earlier section. After a search query has been performed and “relevant” data has been returned, it can be extremely valuable when integrated with large language model inference. This value comes from the additional context the data provides to the model. Large language models come pre-trained and can be used for various inference tasks with just a natural language prompt. However, there are some key things to note about this out-of-the-box, naive inference:
The model’s data is capped at a certain point in time, i.e., data scraped from the internet as it was on the day it was collected.
The model’s data comes from various sources (with different public access levels) but is capped at a certain scale, meaning there’s data siloed away from the model’s training and unknowable to it.
This implies an inherent cut-off in its knowledge base in both timeliness and scope, leading to higher chance of “hallucinations” or, more generally, less relevant responses. LLMs are optimized to output the most statistically likely token to appear after the previous one and will always try to respond to a query, even if its world model or training data lacks information to give the “correct” answer. Changing this cut-off at the training stage requires entirely new training run(s) to update its weights with fresh data. Providing fresh data as context during inference mitigates this knowledge cut-off and avoids retraining at a higher cadence while increasing the chance of an accurate response. This augmentation can be as simple as providing data from private internal documents to a support bot for its replies:
1. User asks what the company’s PTO policy is.
2. Since this policy isn’t public knowledge, the out-of-the-box chatbot is likely to provide the wrong answer.
3. However, when the user asks about the PTO policy, a background process searches the company database for relevant results.
4. The top match from this result is appended to the bot’s context, so that at inference, it is given this top match and the user’s input to provide a more relevant output. An example input prompt in this case could look like:
```Given this result from the human resources policy document: {DATABASE RESULT}, respond appropriately to this user input: {USER INPUT}```
A more complex implementation of an augmentation pattern can allow you to bootstrap chatbot memory without additional frameworks or third parties. For example, a “map-reduce” style pattern follows this general outline:
1. Store every chat session in a table with columns for the session ID, user input messages, and model output messages.
2. In any given session, we can check if it’s the first message of the session or not. If it is, we can follow the same logic outlined above.
3. If it’s not the first session, we can run a “map-reduce” process to provide the previous chat messages as augmented context for inference.
4. The first step of the map-reduce process searches the session table and returns all previous messages, which provide context for an input prompt like this:
```Given these previous messages: {DATABASE RESULT}, write a sharp, concise summary of the chat session.```
5. The resulting output is then provided as additional context for the newest user input, with a prompt that looks something like:
```Given the following summary of the conversation: {EARLIER_RESULT}, respond appropriately to this user input: {USER INPUT}```
6. You may even consider adding another layer of context and combining both techniques. In our HR example, we can write a retrieval layer that brings both the session messages AND the most relevant HR data to the context window and write a prompt that includes both.
```Given this result from the human resources policy document: {DATABASE RESULT} and the following summary of the conversation: {earlier_result}, respond appropriately to this user input: {USER INPUT}```

Hopefully, this initial overview can help illustrate the value of augmenting inference with the data from the retrieval step. As these examples have shown, we can both increase inference accuracy and decrease the need for additional training or fine-tuning by leveraging these techniques.
Generation, or “G”
Alright, on to the last step. The G in RAG is the part that really grabs the headlines, since it’s the part most people know (assuming they’ve prompted a chatbot at least once in the last couple years). A lot has been written about generative AI, both from a technical and social perspective. Like I said earlier, I will not be saying much about the topic from a broad perspective. Instead, I’ll discuss alternative applications that are not chatbots per se, as well as some techniques to help mitigate common weaknesses in the generation process.
First, from a use case perspective, a surprisingly one for businesses is report generation. While I certainly don’t think these technologies are uh a machine god intelligence yet, they are really quite good at summarizing documents! In many enterprise settings, summarizing a large collection of unstructured data from various sources is a) an extremely time-consuming task b) a large part of the task to be done before the actual valuable task itself. If we extend our earnings transcripts example from the very first section, you can imagine a scenario where someone is tasked with answering “what has been the change in sentiment expressed in earnings calls over the last year?”. The valuable task is finding the sentiment shown on the calls. But before you can do that, you need to consume all of the content in the transcripts and then synthesize it into a clear perspective. An application designed with some of the concepts mentioned in this piece could consume and index all of the transcript content, find the most relevant sections of each call through the semantic concepts expressed in those sections, and create a structured report highlighting and summarizing them.
Sounds great, right? But like any complex system, it’s certainly not perfect. Common issues at this stage all stem from the fact that out of the box, generative responses are probabilistic and unstructured natural language text. This isn’t compatible with the non-generative, deterministic components of most systems. This affects our report example. As most email-job people know, reports are often structured documents with specific components and sections dictated by an organization’s standards and purposes. Unstructured text doesn’t play well with that. One way to mitigate this then is to enforce structured responses. I hinted at this above when I said that out of the box the responses are unstructured text. If we move past that default setting though, there are a couple different ways to enforce some structure to these generative outputs. If you’re developing in Python or JS, you can use Jason Liu’s instructor library. While other frameworks exist, I prefer the lightweight approach of instructor. You simply define a data schema (i.e., using Pydantic) and pass it to the model as part of the inference call (example below):
class ExampleClass(BaseModel):
transcript_name: str
transcript_date: bool
cited_section: str
resp = await client.chat.completions.create(
response_model=ExampleClass,
model=deployment_name,
messages=[
{
"role": "system",
"content": ("You consistently output JSON."),
},
{"role": "user", "content": "PROMPT HERE"},
],
)
At this point, most of the major model providers offer some version of this feature, including OpenAI and Mistral’s recent class of models, and as of December 2024, Ollama offers it for others like Llama3.2. Under the hood, most of these implementations are utilizing function calling to wrap the model provider client, convert the data model to a function schema, and validate the model response against the schema in the function being called. It’s fairly simple on the surface, but it allows different components to integrate as long they are using the same schemas for data interchange.
Let’s extend our example once more to drive the point home. In our report generation scenario, we need data provenance around the report response. In plain English, we need to be able to trace the report’s sections to the source data used to generate the response. Using structured data schemas and function calling, we can set something like this up without anything more complex than our structured replies, since they:
- enforce explicit connections between an inference and the source data, requiring every claim to link to specific pieces of source material.
- enable programmatic verification. With the information organized into well-defined fields, code can be written that automatically checks each claim against its cited sources. For example, if an insight claims to quote a specific span of text from a source document, we can verify that the text actually appears at those exact coordinates.
That concludes the generation part of the system. If you’re interested in exploring this space in more depth, this is where the (unfortunately named) concept of prompt engineering comes into play. There is a lot of nuance involved in crafting the prompts for generative inference, and this piece only scratched the surface with very simple prompt examples. For more details on this particular area, I recommend starting with Eugene Yan’s prompting overview.
Conclusion
So…what is RAG? Well, like we covered at the beginning, RAG is a technique to provide relevant context for generative AI inference. While simple enough on the surface, this technique opens up a huge field of questions, like How do we provide this context? Where is this context coming from? What makes it relevant? The truth is every organization and developer will have different answers to these questions, determined by their use case. That’s a bit of a copout, but in the end, defining RAG wasn’t the true purpose of this piece. The real idea behind was to provide a pragmatic and grounded perspective on this emerging space, as well as some techniques and ideas that can be implemented without too many resources to develop a RAG system. The next step after grokking some of these techniques is evaluating the operational concerns of a RAG system, so thinking about things like:
Do we leverage third party providers (like OpenAI) for models and hosting or going open source (Llama 3.2 on either a cloud platform or an on-premise hosting service)?
Do we use standard out-of-the-box models (embedding or conversational) or do we need to fine-tune them for a specific subject area or vertical?
Should we integrate vector storage into our existing systems or create new, stand-alone systems for generative AI that are up to date with the existing systems?
How do we monitor accuracy and performance for a probabilistic system versus a more traditional deterministic one?
How can we optimize our systems for rapid experimentation and changes?
If you’re looking to take a step past simple demos and integrate a system like this or are looking for answers around some of these next level questions, our team is always happy to chat, you can reach us: here.
Glossary:
- BM25 (Best Match 25): A ranking function used in search engines that scores how relevant a document is to a search query, taking into account both term frequency and document length.
- Chunking: The process of breaking down large documents into smaller, manageable pieces that can be processed more efficiently by AI models.
- Embedding: A way of converting text, images, or other data into lists of numbers (vectors) that capture their meaning and allow computers to process them more effectively.
- FAISS (Facebook AI Similarity Search): An open-source library developed by Facebook for efficient similarity search and clustering of dense vectors.
- LLM (Large Language Model): AI models like GPT that can understand and generate human-like text.
- pgvector: A PostgreSQL extension that enables vector similarity search operations directly within a PostgreSQL database.
- RAG (Retrieval Augmented Generation): A technique that enhances AI responses by first retrieving relevant information from a knowledge base, then using that information to generate more accurate and contextual responses.
- Semantic Search: A search method that understands the intent and contextual meaning of search terms, rather than just matching exact keywords.
- Vector Database: A specialized database designed to store and efficiently search through embeddings (vector representations of data).
- Vector Embedding: The numerical representation (usually a list of numbers) of text, images, or other data that captures their meaning in a way that computers can process.
References:
As always, development is always done on the shoulders of giants. While there are definitely plenty of other great resources out there, the following are ones that I find myself consistently coming back to. They offer knowledge gained by true experience in the nitty gritty of this emerging space, while keeping it down-to-earth, applicable, and geniunely interesting. Cannot recommend their work enough.
- Instructor: A Python library for structured outputs in large language models (more languages are being added!) led by Jason Liu. Huge fan of the work they're doing, Jason is a great resource for developing in this space and is always releasing great documentation, guides, and these days, workshops as well.
- Hamel Husain's blog and technical writing is another great resource for developing in this space. I referenced his tweet earlier but his work covers so much more than just witty 140 character explainers. He puts out so much quality writing, guides, and technical pieces. As you can see, I'm a huge fan of his work as well.
- Eugene Yan's blog and technical writing is the third giant when it comes to actual, hands-on keyboard gen AI development. Like Jason and Hamel, he puts out so much outstanding work and is really dealing with these systems at scale, day in and day out.